DeepSeek Janus Pro Image Generator: Multimodal Image Model Breakdown
Hot on the heels of the DeepSeek R1, which came out last week and had a massive impact on both the AI-ML community and the mainstream community, I want to cover DeepSeek’s new multimodal understanding and generation model. I am going to show what it can do, talk a little bit about it, and highlight how it shows a team thinking about different ideas than a lot of the mainstream labs. Whatever they are doing in their research team, they are not just following the hip and happening way of building these models right now.

What Sets DeepSeeks New Image Apart
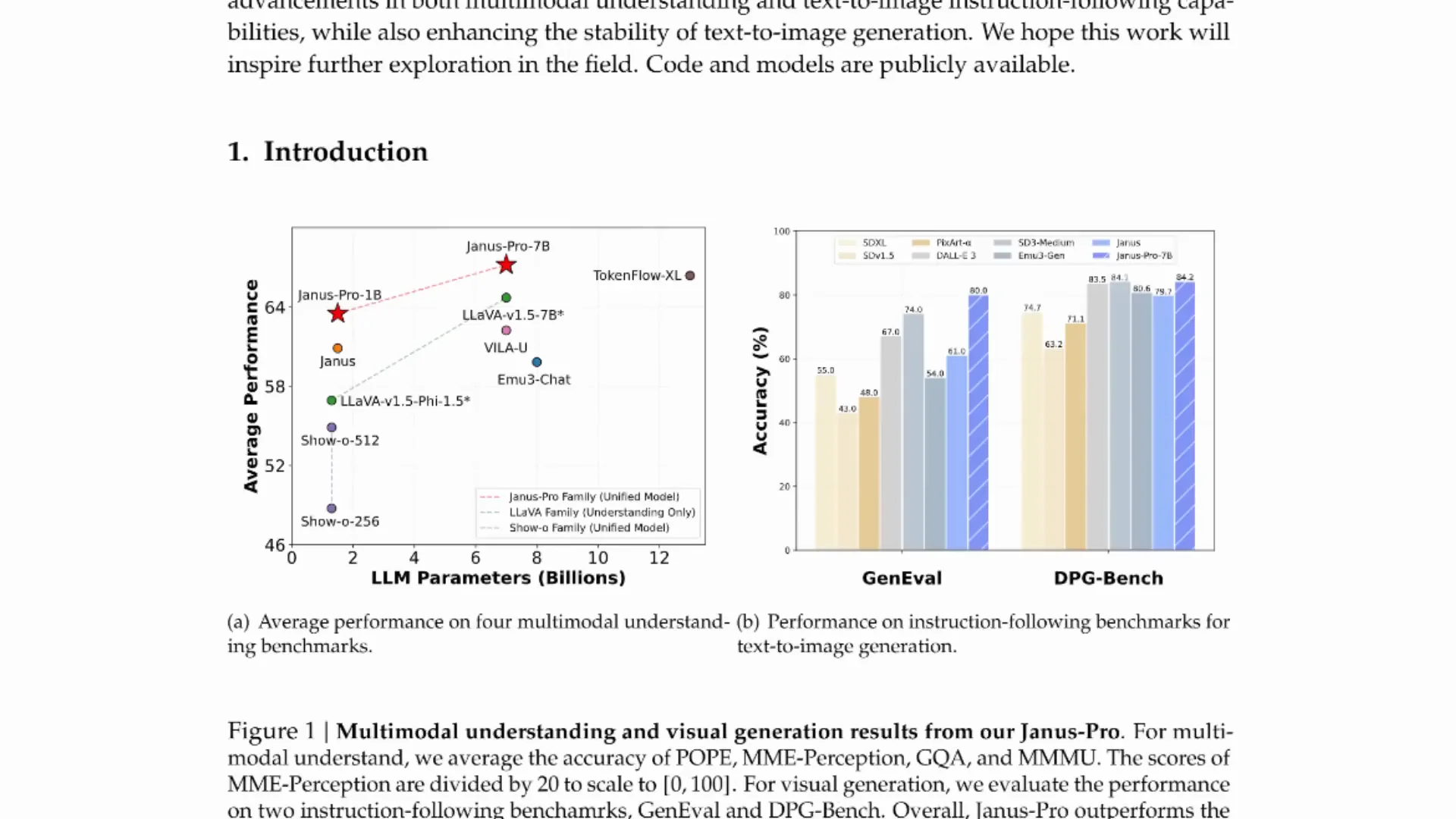
Most models in gen AI at the moment fall into one of two categories - language models or vision models. We have vision models that make movies and other media, and we have combined versions where a vision encoder understands an image and helps a language model interpret it.
This Janus Pro model goes beyond that. It not only has a vision encoder for visual question answering and image understanding, but it can also take text input, tokenize it, and generate new images. You get both image understanding with answerable questions and text-to-image generation, with outputs getting on par with some of the early diffusion models out there.
This is not the first model like this from DeepSeek. Janus is their third paper and at least the third model in this direction. With Janus Pro they upscale it, make the model much bigger, and make the whole thing work better. In the comparisons, for prompts like the face of a beautiful girl or a glass of red wine, the new 7 billion Pro model produces clearly better images than the smaller earlier model.

How DeepSeeks New Image Works
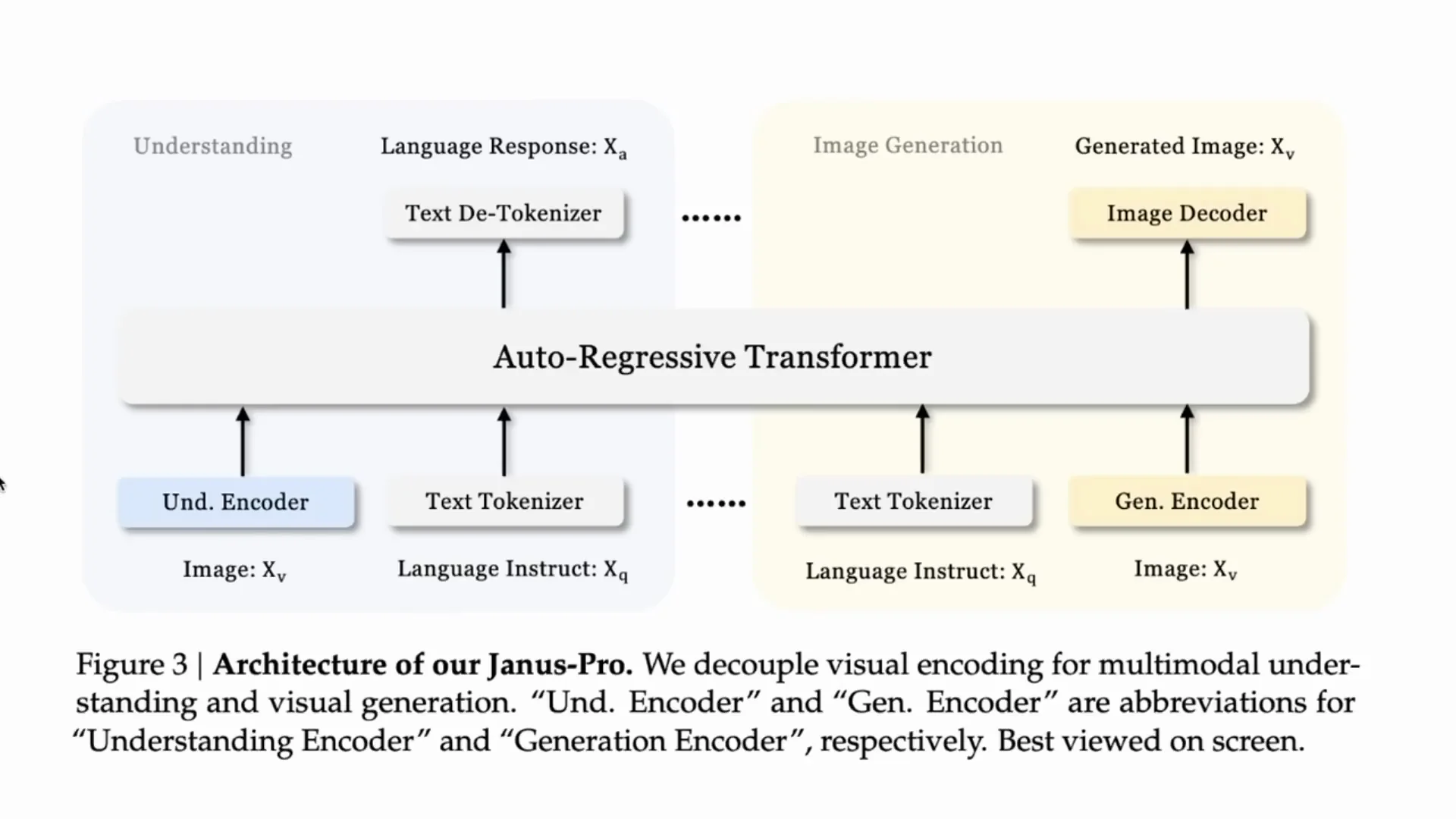
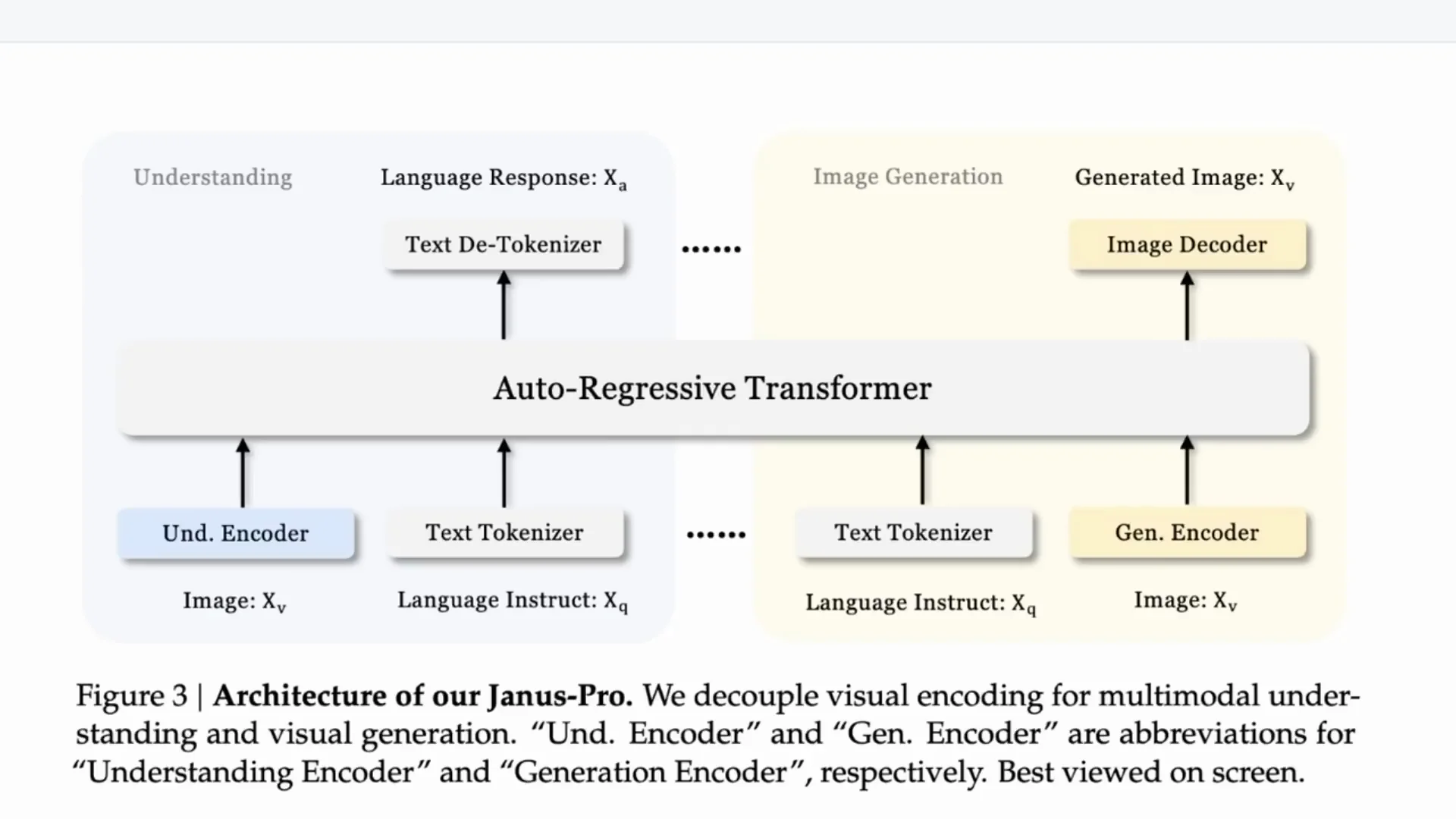
You have two pathways:
- Image to tokens for understanding - and then text tokens out.
- Text tokens in - and then through a generation phase to images out.
Understanding - Image to Text
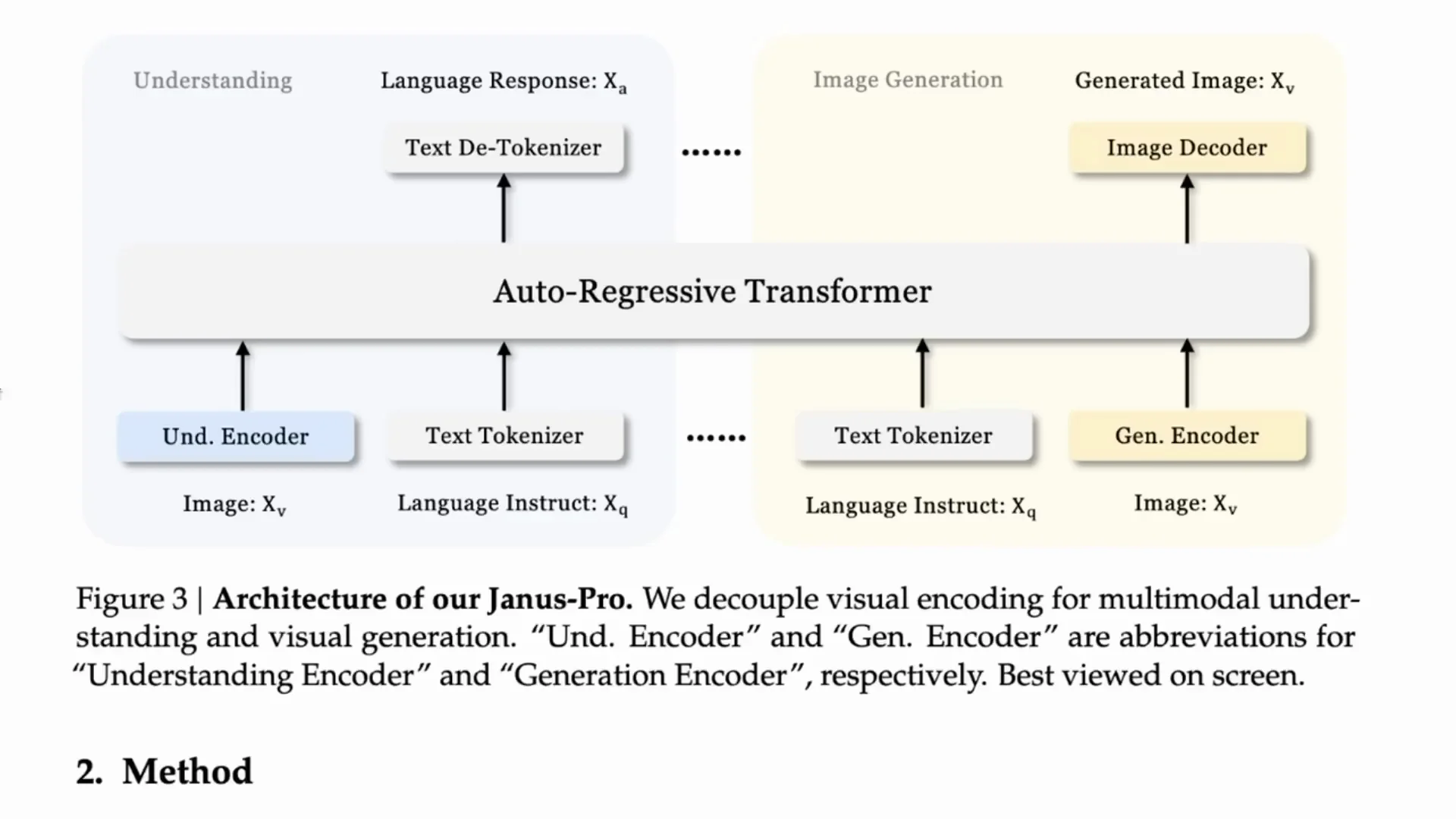
For the understanding encoder they use a SigLIP model - a more modern version of CLIP. SigLIP came from Google and is used in systems like PaLI-Gemma and in various image understanding research from Google. The image goes through SigLIP for encoding, text is encoded, and then both go into an autoregressive model. That model generates the text response token by token.
Generation - Text to Image
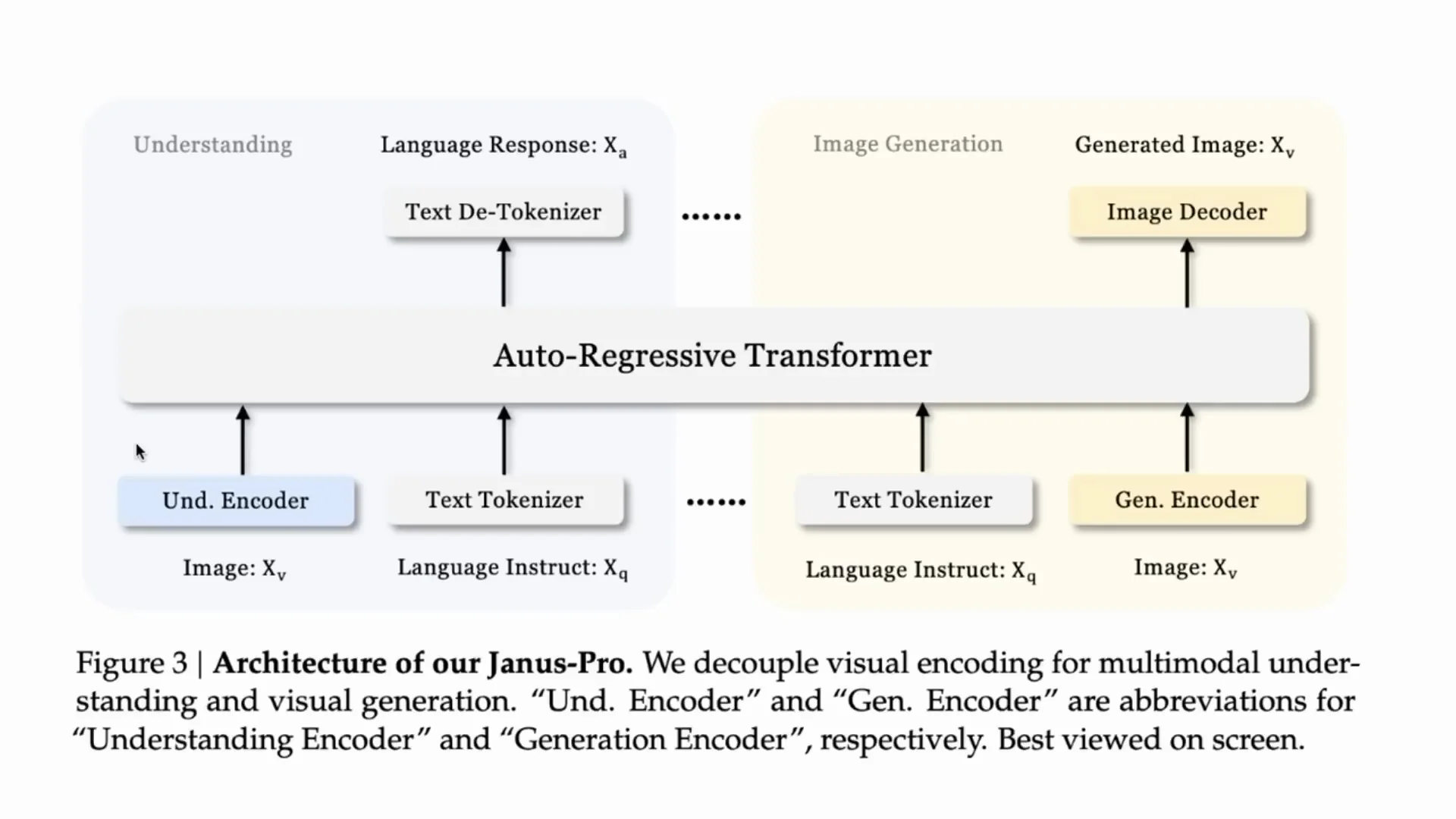
For generation, text goes into a generative encoder which then runs through an autoregressive system to predict the image as a sequence. People normally use diffusion and perhaps a U-Net for this kind of task. Here they use a vector quantization tokenizer - a real throwback.
Vector quantization is not new. The paper they cite builds on earlier attempts where people used autoregressive models to compete with diffusion. The idea goes back to VQGAN and before that to VQ-VAE - one of the current heads of the Gemini team was a co-author on VQ-VAE. The idea is to move from continuous embeddings to discrete representations. With VQGAN you generate codebooks for lookups that translate to specific outputs, and that works quite well in an autoregressive way where you predict token after token.
I bring this up to show that this team is thinking differently. Right now almost all image models use diffusion for generation. Autoregressive image models were common in the past, and they are bringing that approach back in a serious way.
What DeepSeeks New Image Can Do
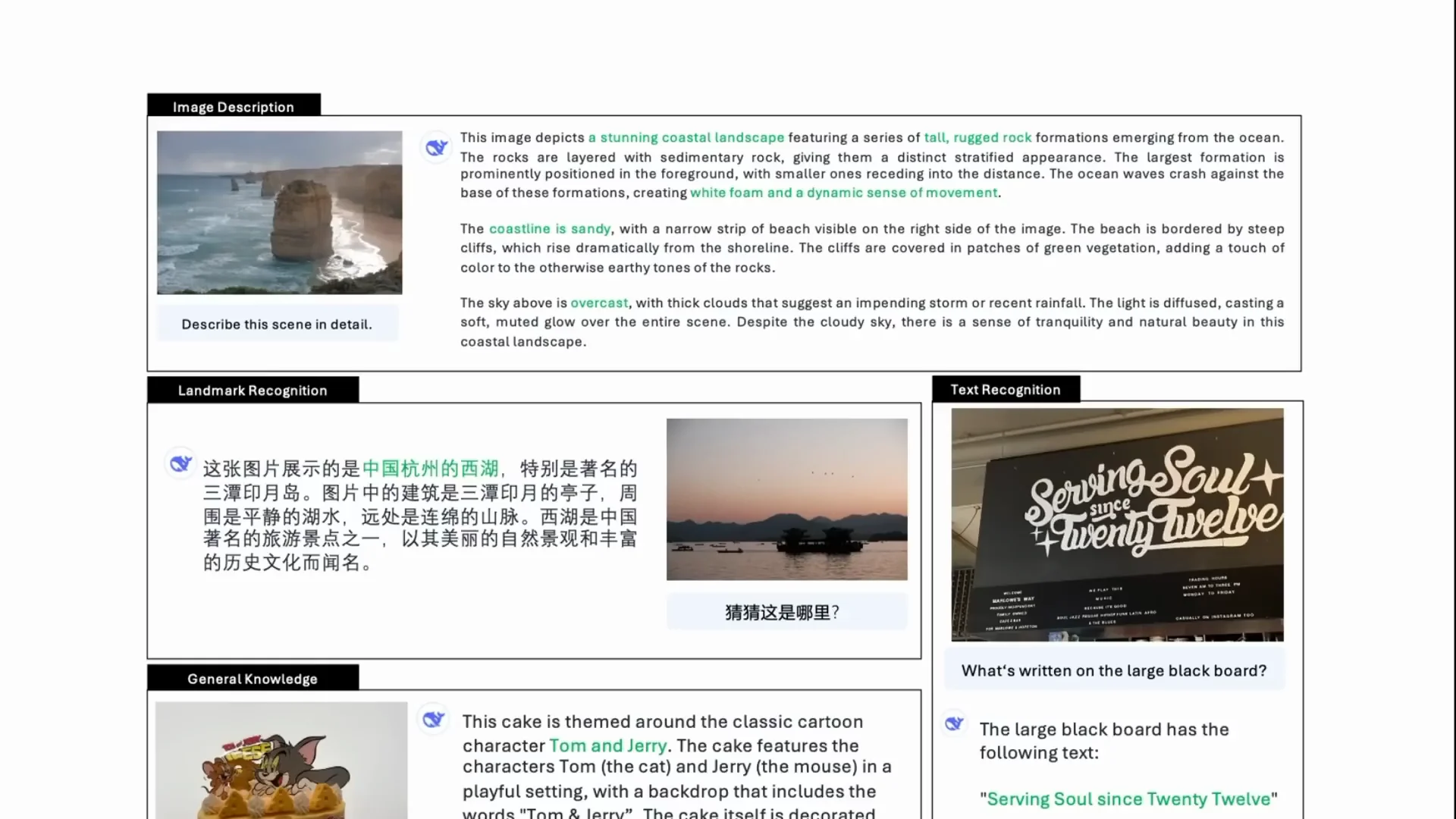
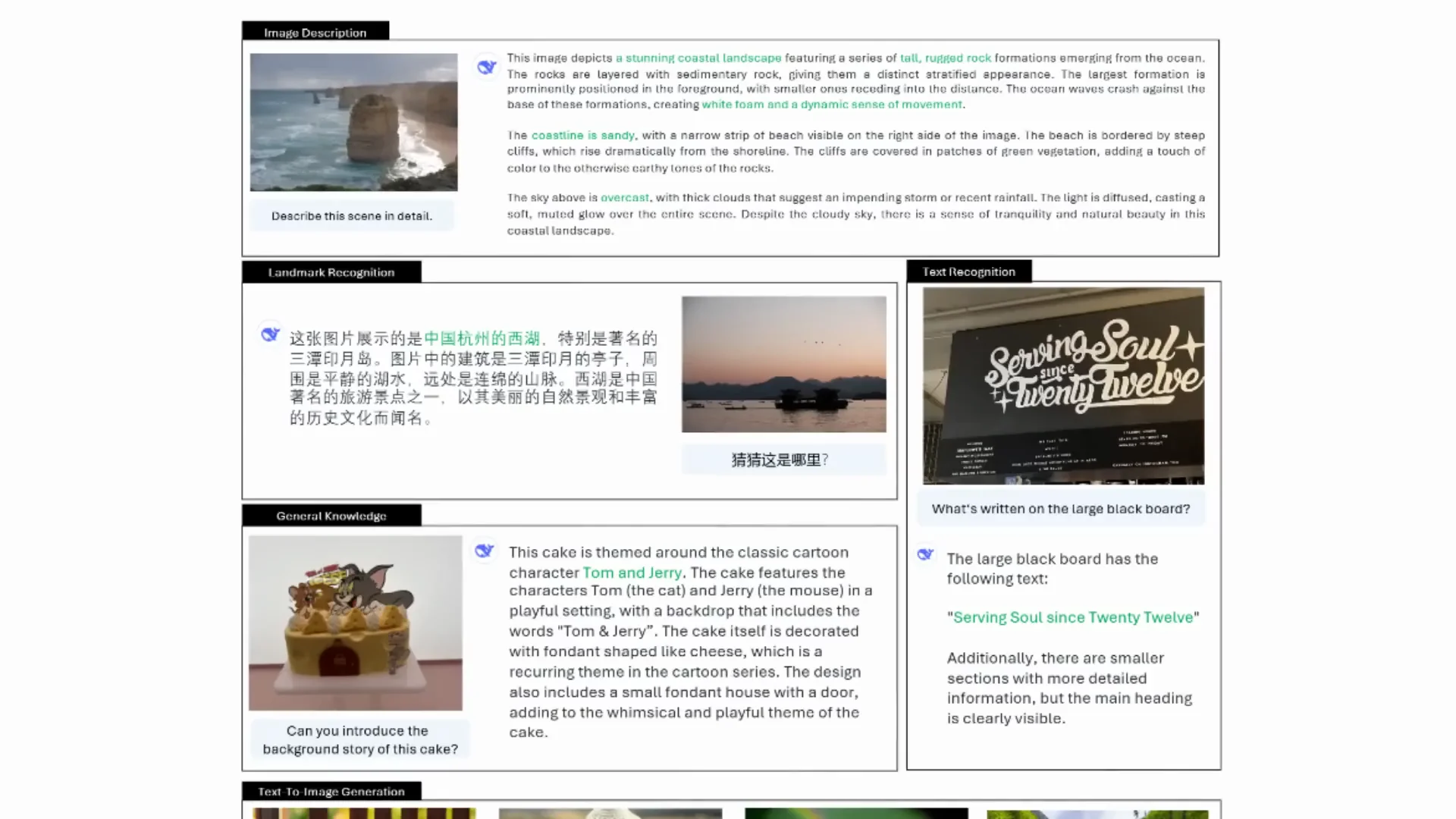
It is able to do strong text-and-image descriptions in English and Chinese. It can describe scenes in detail, handle OCR-type tasks, and, because it has an autoregressive language model in the loop, it often goes beyond surface-level recognition. In a question like “Can you introduce the background story of the cake,” it can work out Tom and Jerry and explain that context.
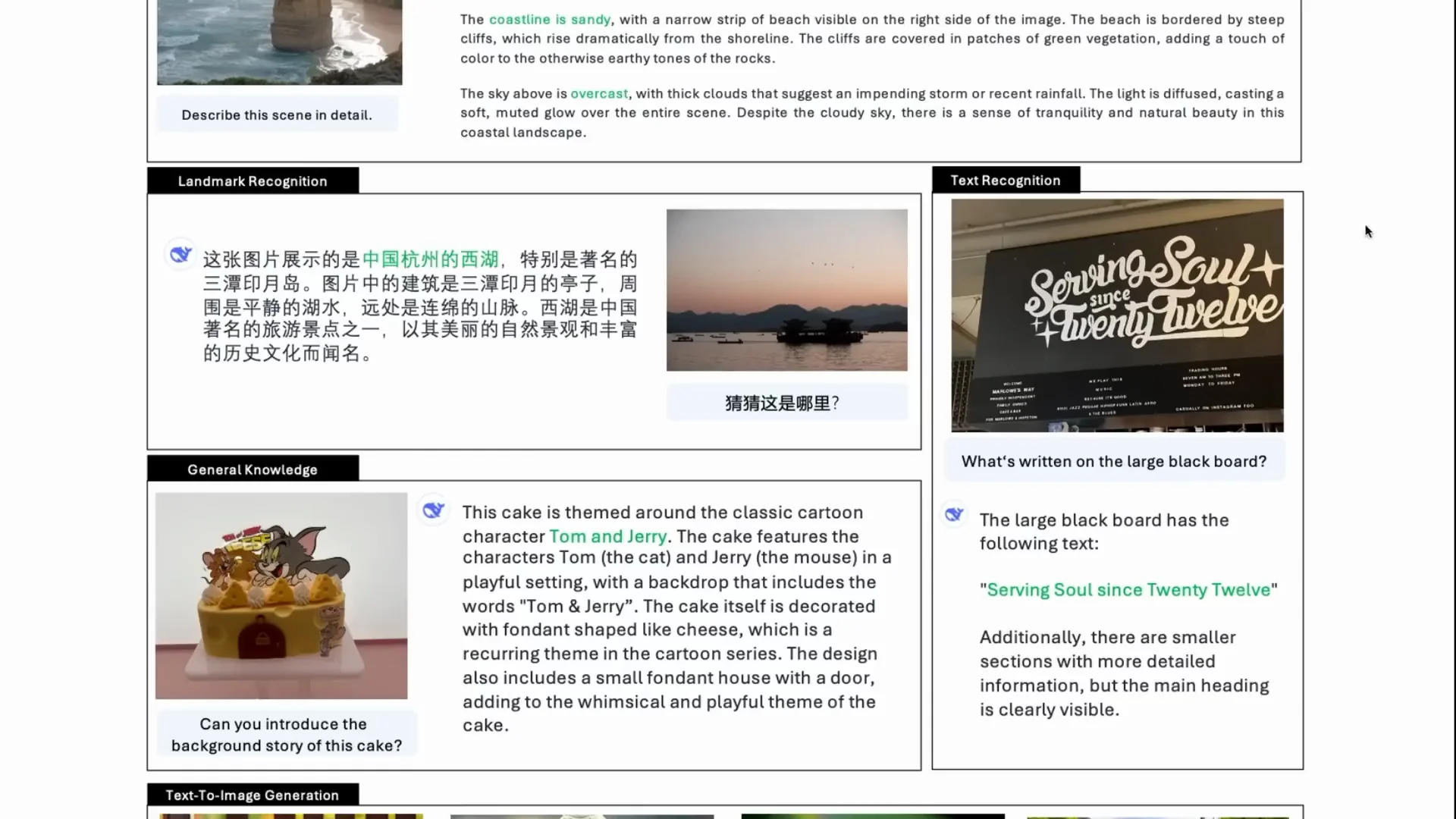
The same model is then used for text-to-image generation. The understanding path uses SigLIP. The generation path flips to codebooks and a VQ tokenizer. The images look pretty good. They are not super high resolution and probably not as good as many diffusion models, but the fact that one model can do both tasks is impressive.
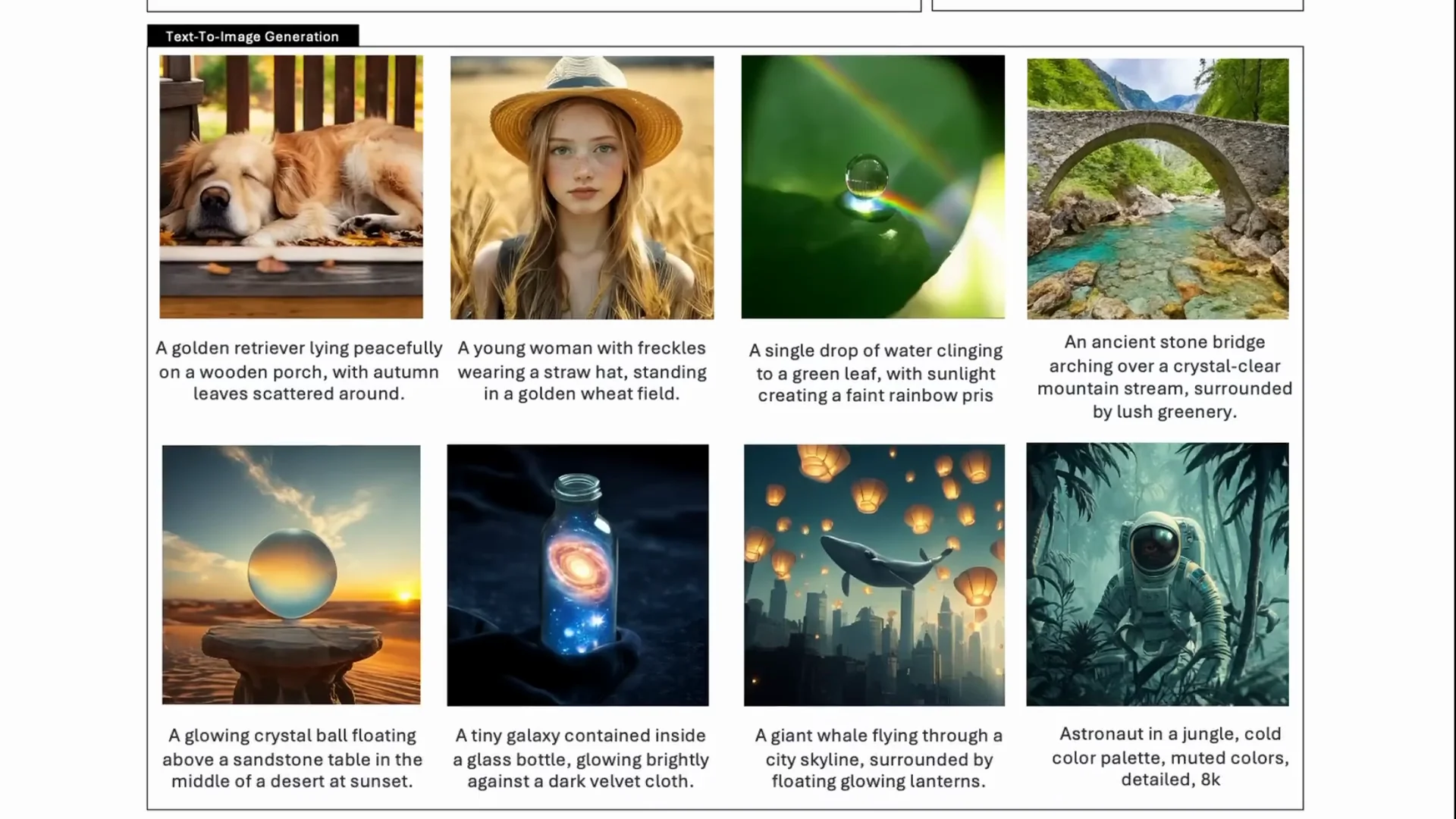
The VQ Tokenizer Flow

For visual generation tasks, they use the VQ tokenizer to convert images into discrete IDs. After flattening the ID sequence into a 1D vector, they use a generation adapter to map those codebook embeddings into the input space of the LLM. This is a unique way of doing the integration and not something many people have done recently.
Running DeepSeeks New Image
I ran this in Colab on an A100 GPU. It will not fit on a T4 GPU - the model is too big unless you quantize. The download is roughly 15 GB.
They provide components in Transformers for the base causal LM, plus their own library for the multimodal causal LM and the chat processor. To do the SigLIP path you need their processors - a tokenizer for text and a visual chat processor - and then the model.
Text-to-Image Example
For image generation you set up a standard conversation. I used a user message like “a stunning ginger Manx cat looking at the camera in the style of a Nat Geo portrait.” The assistant is primed to respond, and that response comes out as an image. The setup generated 16 different images and saved them, giving me 16 slightly different ginger Manx cats.
I then asked for “Donald Trump as the new Roman emperor of the United States in an anime style.” It can do it. It understands Donald Trump and can draw him in anime, with Roman elements and United States elements mixed into the picture. You can generate lots of cartoons and anime with this. It is not censored, so be careful and use at your own risk.
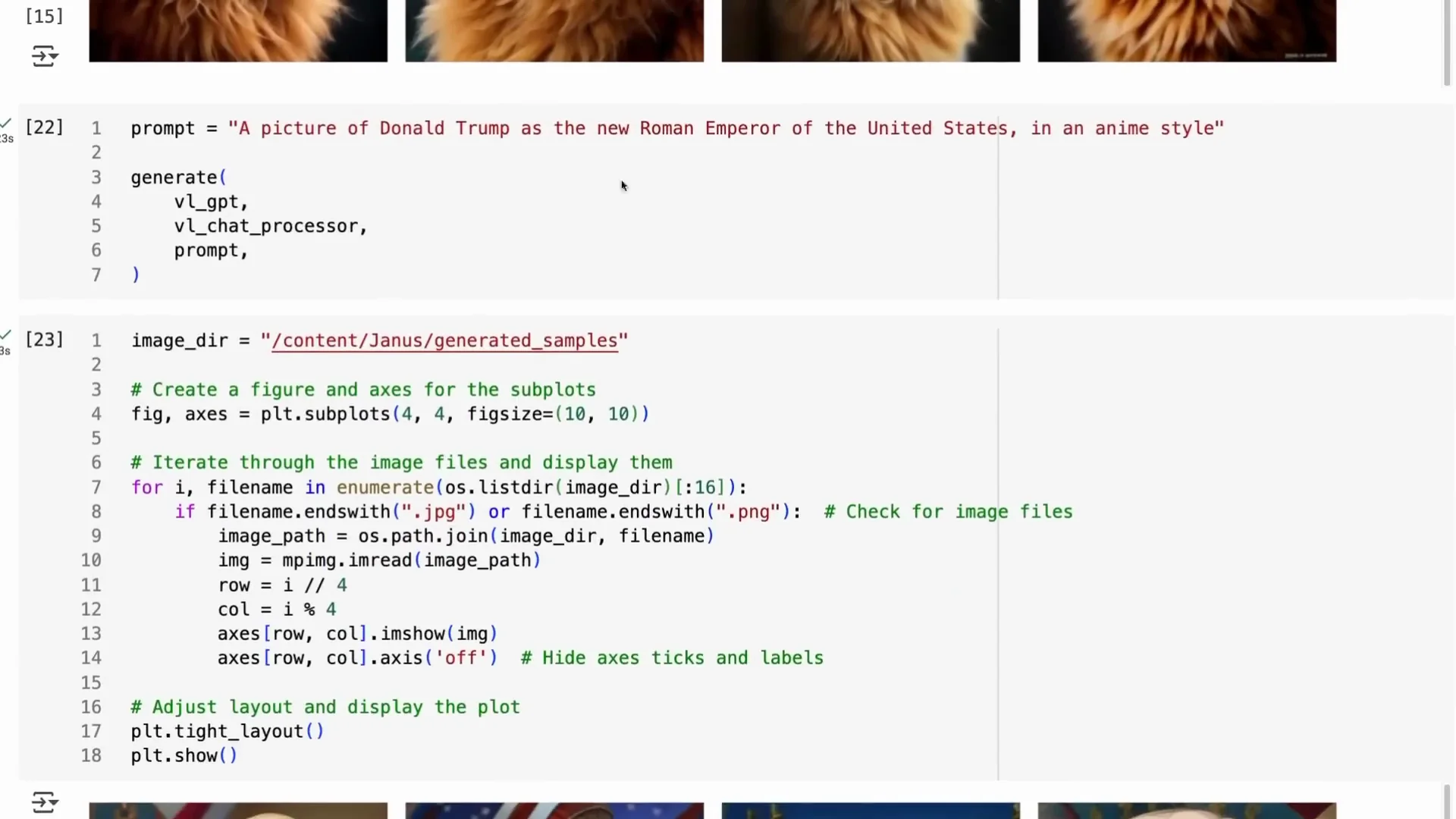
Image Understanding Example
For image understanding we switch to the SigLIP path. You load the same model, pass in the tokenizer and processor, and feed it an image. I used a photo showing Mount Fuji and asked, “What is this place - tell me its history.”
The model correctly identified Mount Fuji, noted its symmetry, and then gave historical context - formation over millions of years, cultural significance, and details like the Edo period. Because I asked for history, it provided it. You could also ask follow-ups about the town visible in the shot or objects in the sky.
Reflections on the Approach

It will be interesting to see if more modern models move toward a merger of these approaches. I do not know if this exact setup would work with diffusion, though it is possible they could modify it. I find it notable that they chose an autoregressive route for image generation rather than following the diffusion-first approach that dominates right now.
You will need a strong GPU to run it. An A100 works well. On a local machine, 24 GB of VRAM might fit it, but a T4 is not going to cut it in this state.
Final Thoughts
DeepSeeks New Image shows a capable multimodal model that understands images with a SigLIP encoder and generates images with an autoregressive VQ-tokenized pipeline. It is not chasing the diffusion trend, yet it delivers solid text-to-image results and thorough visual question answering in one model. The approach is refreshingly different, the results are promising, and the code path is straightforward if you have the GPU headroom.
Recent Posts

How to use Grok 2.0 Image Generator?
Learn how to access Grok 2.0’s AI image generator (Premium required), write better prompts, and avoid pitfalls like real people and brands. Step-by-step tips.
How to use Instagram AI Image Generator?
Use Meta AI in Instagram DMs to turn text into images—and even animate them. It’s free, fast, and built in. No external apps needed; create art right in chat.
Leonardo AI 2026 Beginner’s Guide: Create Stunning Images Fast
Learn Leonardo AI step by step—sign up, explore Home, and generate or enhance photos with free, powerful tools. A quick, clear starter for beginners.